1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
| import re
import os
import sys
import time
import datetime
import math
import imghdr
import shutil
import random
import string
import tinify
import urllib
import sqlite3
import operator
from hashlib import md5
from qiniu import Auth, put_file, etag, BucketManager
import validators
# 七牛配置
ak = ' '
sk = ' '
domain = ' ' # 上传域名
bucket = ' ' # 空间名称
tinify.key = ' ' # 设置tinipng的key
q = Auth(ak, sk) # 七牛认证
#初始化BucketManager
Bucket_Manager = BucketManager(q)
md_loc = '' # md地址
need_zip = True
today = datetime.date.today()
yyyymmdd = today.strftime('%Y%m%d') #创建时间变量,用于图片起名
total, success, failure, ignore = 0, 0, 0, 0
def upload_file(upload_file_name):
'''
根据给定的图片名上传图片,并返回图片地址和一些上传信息
'''
global success , ignore , failure
#rstr = str(time.time())+''.join(random.sample('abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ', 12))
#key = md5(rstr.encode('utf-8')).hexdigest() # 上传到七牛后的图片名
key = yyyymmdd+"_"+os.path.splitext(os.path.basename(sys.argv[1]) )[0]+"/image"+('{0}'.format(success+1))+os.path.splitext(upload_file_name)[1]
# 上传到七牛后的图片名:上传日期-MD文件名/image序号.png or jpg
mime_type = upload_file_name[upload_file_name.rfind('.') + 1:]
token = q.upload_token(bucket, key)
ret, info = put_file(token, key, upload_file_name, mime_type=mime_type, check_crc=True)
if ret['key'] == key and ret['hash'] == etag(upload_file_name):
success = success + 1
return 'http://' + domain + '/' +key, info
failure = failure + 1
return None
def transfer_online_img(old_link):
'''
根据给定的图片链接上传图片到七牛,并返回图片地址和一些上传信息
'''
global success , ignore , failure
if validators.url(old_link) is not True:
ignore = ignore + 1
print('invalid url, ignore')
return None
# maybe a url
# already from qiniu
if old_link.find(domain) != -1:
ignore = ignore + 1
print('already in qiuniu, ignore')
return None
# omit the query string section like:?arg1=val1&arg2=val2 in the url
if old_link.find('?') != -1:
old_link = old_link[: old_link.index('?')]
#key = yyyymmdd + "-" +''.join(random.sample('abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ', 6))
key = yyyymmdd+"_"+os.path.splitext(os.path.basename(sys.argv[1]) )[0]+"/image"+('{0}'.format(success+1))
# 上传到七牛后的图片名:上传日期-MD文件名/image序号
ret, info = Bucket_Manager.fetch(old_link, bucket, key)
if ret['key'] == key :
success = success + 1
return 'http://' + domain + '/' +key
failure = failure + 1
return None
def cached_img_url(img_loc_path):
'''
根据给定的本地图片绝对路径,转换成一个网上路径。
如果本地缓存中有,则直接读取并返回,如果没有,则上传后返回。
'''
conn = sqlite3.connect(md_loc + './img_hash_cache.db')
cursor = conn.cursor()
try:
cursor.execute('''
CREATE TABLE img_cache_table (
img_hash TEXT,
real_p TEXT,
img_url TEXT,
u_info TEXT
)
''')
except Exception as e: pass
img_hash = md5(open(img_loc_path, 'rb').read()).hexdigest() # 图片的hash值,用来确定图片的唯一性,避免多次上传,浪费流量
cursor.execute("SELECT img_url FROM img_cache_table WHERE img_hash='%s'" % img_hash) #根据图片的hash值来找缓存下来的图片网址
select_res = [row for row in cursor]
img_url = (select_res[0][0] if select_res and len(select_res) > 0 and select_res[0] and len(select_res[0]) > 0 else None)
remote_exists = False
if img_url:
try: remote_exists = urllib.request.urlopen(img_url).code == 200
except Exception as e:
print('#warning: 网址不存在 :', img_url)
remote_exists = False
if not img_url or not remote_exists: # 如果没有查到图片的网址,或者网址失效
print('上传图片 :', img_loc_path)
img_url, uinfo = upload_file(img_loc_path) # 接取上传后的图片信息
if not img_url: # 如果图片地址为空,则说明上传失败
print('#warning: 上传失败')
conn.close()
return None
else:
if not remote_exists: cursor.execute('INSERT INTO img_cache_table VALUES(?,?,?,?)', (img_hash, img_loc_path, img_url, str(uinfo))) # 如果上传成功,则直接缓存下来
else : cursor.execute("UPDATE img_cache_table SET img_url='%s', u_info='%s' WHERE img_hash='%s'" % (img_url, str(uinfo), img_hash))
conn.commit()
conn.close()
return img_url
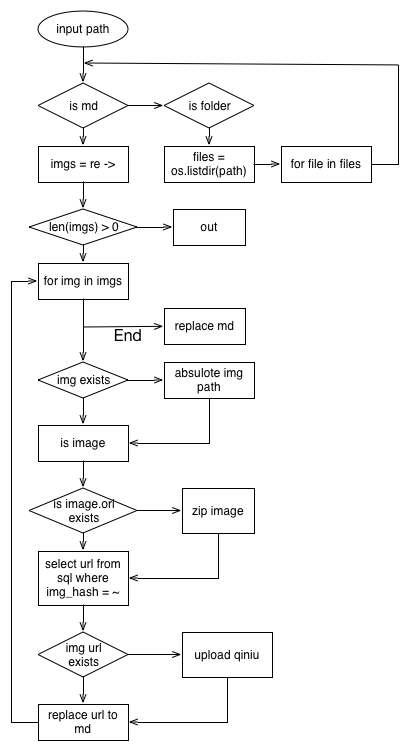
def md_img_find(md_file):
'''
将给定的markdown文件里的图片本地路径转换成网上路径
'''
post = None # 用来存放markdown文件内容
global total , success , failure , ignore
with open(md_file, 'r',encoding='utf-8') as f: #使用utf-8 编码打开 by chalkit
post = f.read()
matches = re.compile('!\\[.*?\\]\\((.*?)\\)|<img.*?src=[\'\"](.*?)[\'\"].*?>').findall(post) # 匹配md文件中的图片
if matches and len(matches) > 0:
for sub_match in matches: # 正则里有个或,所以有分组,需要单独遍历去修改
for match in sub_match: # 遍历去修改每个图片
total = total + 1
if match and len(match) > 0:
print("match pic : ", match)
if not re.match('((http(s?))|(ftp))://.*', match): # 判断是不是已经是一个图片的网址
loc_p = match
if not os.path.exists(loc_p) or not os.path.isfile(loc_p): # 如果文件不存在,则可能这是用的一个相对路径,需要转成绝对路径
loc_p = md_file[:md_file.rfind('\\')+1] + match # Windows中 md_file的本地路径为反斜杠\\, match的相对路径为 "MD标题\图片文件名"
if os.path.exists(loc_p) and os.path.isfile(loc_p):
if imghdr.what(loc_p): # 如果是一个图片的话,才要上传,否则的话,不用管
if need_zip:
o_img = loc_p + '.ori' # 原始未压缩的图片
try:
if not os.path.isfile(o_img) or not imghdr.what(o_img): # 如果没有的话,那就需要进行压缩处理
print('压缩图片 :', loc_p)
s_img = tinify.from_file(loc_p)
s_img.to_file(loc_p + '.z')
os.rename(loc_p, loc_p + '.ori')
os.rename(loc_p + '.z', loc_p)
except Exception as e:
print('#warning: tinypng压缩出问题了,图片未压缩。')
file_url = cached_img_url(loc_p) # 获取上传后的图片地址
if file_url: # 在图片地址存在的情况下进行替换
print('图片地址是 : ', file_url)
post = post.replace(match, file_url) # 替换md文件中的地址
else:
ignore = ignore + 1
print('#warning: 不是一个图片文件 :', loc_p)
continue
else:
ignore = ignore + 1
print('#warning: 文件不存在 :', loc_p)
else:
print('markdown文件中的图片用的是网址 :', match)
file_url = transfer_online_img(match) # 获取上传后的图片地址
if file_url: # 在图片地址存在的情况下进行替换
print('图片地址是 : ', file_url)
post = post.replace(match, file_url) # 替换md文件中的地址
if post: open(md_file, 'w',encoding='utf-8').write(post) #如果有内容的话,就直接覆盖写入当前的markdown文件
#仍然注意用uft-8编码打开
print ('Complete!')
print (' total :%d' %(total))
print (' success :%d' %(success))
print (' failure :%d' %(failure))
print (' ignore :%d' %(ignore))
def find_md(folder):
'''
在给定的目录下寻找md文件
'''
if len(folder) > 3:
if folder[folder.rfind('.') + 1:] == 'md': md_img_find(folder) # 判断是否是一个md文件,如果是的话,直接开始转换
elif os.path.isdir(folder):
files = os.listdir(folder)
# 读取目录下的文件
for file in files:
curp = folder + '/' + file
if os.path.isdir(curp): find_md(curp) # 递归读取
elif file[file.rfind('.') + 1:] == 'md': md_img_find(curp)
if __name__ == '__main__':
if len(sys.argv) >= 2:
if len(sys.argv) >= 3:
need_zip = sys.argv[2] == '1'
c_p = sys.argv[0]
md_loc = c_p[:c_p.rfind('/') + 1]
bak_md = '%s.bak' % (sys.argv[1])
shutil.copyfile(sys.argv[1], bak_md) # 在执行改动之前备份原MD文件,可手动删除
print('origin markdown file backup in: %s' % (bak_md))
find_md(sys.argv[1])
|